Depth estimation is a crucial step towards inferring scene geometry from 2D images. The goal in monocular depth estimation is to predict the depth value of each pixel or inferring depth information, given only a single RGB image as input.
Depth information is important for autonomous systems to perceive environments and estimate their own state. Traditional depth estimation methods, like structure from motion and stereo vision matching, are built on feature correspondences of multiple viewpoints. Meanwhile, the predicted depth maps are sparse. Inferring depth information from a single image (monocular depth estimation) is an ill-posed problem. With the rapid development of deep neural networks, monocular depth estimation based on deep learning has been widely studied recently and achieved promising performance in accuracy. Dense depth maps are estimated from single images by deep neural networks in an end-to-end manner.
The Monocular Depth Estimation problem can be primarily solved using two methods.
1. Treating the dense depth map as a soft segmentation map of the environment, this method allows for the usage of networks trained on semantic and instance segmentation, onto depth estimation problems.
2. Treating the dense depth map generation as a purely generative task. In this methodology, the depth-map is not discretized, and is treated as a transformation of the input RGB image. This method then proposes, monocular depth estimation as a image translation process that converts the representation of the RGB image into the depth map.
In our project, we approached the depth estimation problem as a generative task and used a pix2pix GAN augmented by a novel gradient-error minimizing loss for image generation.
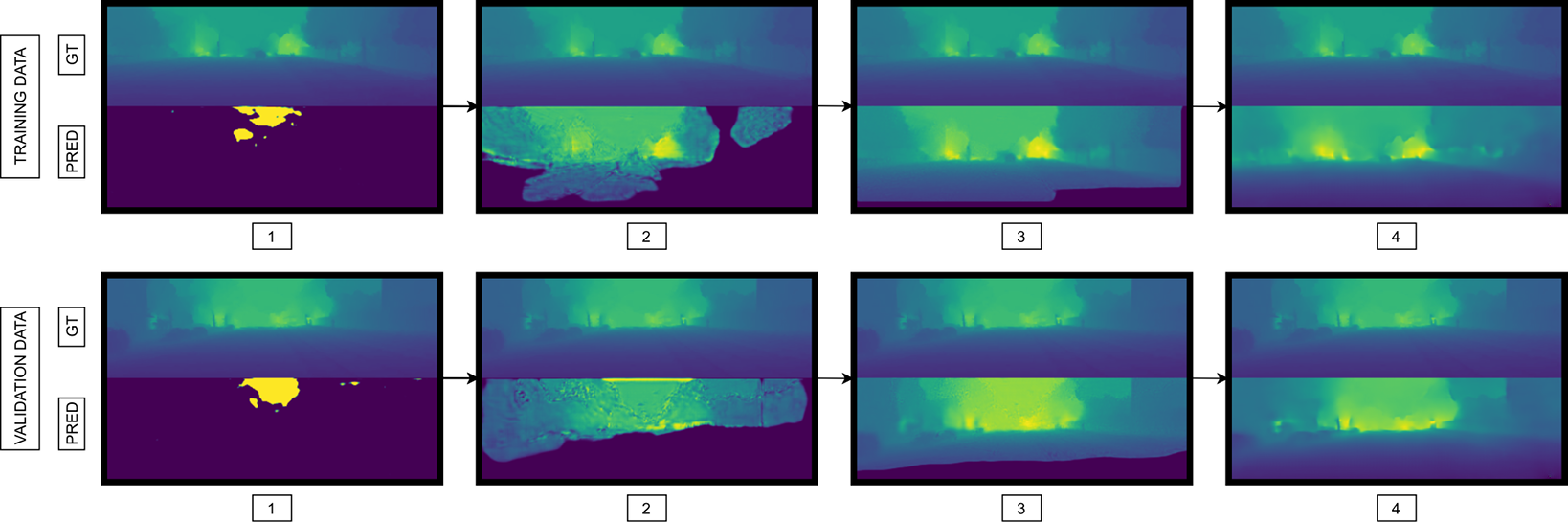
Folowing are the results from our project.
Media:
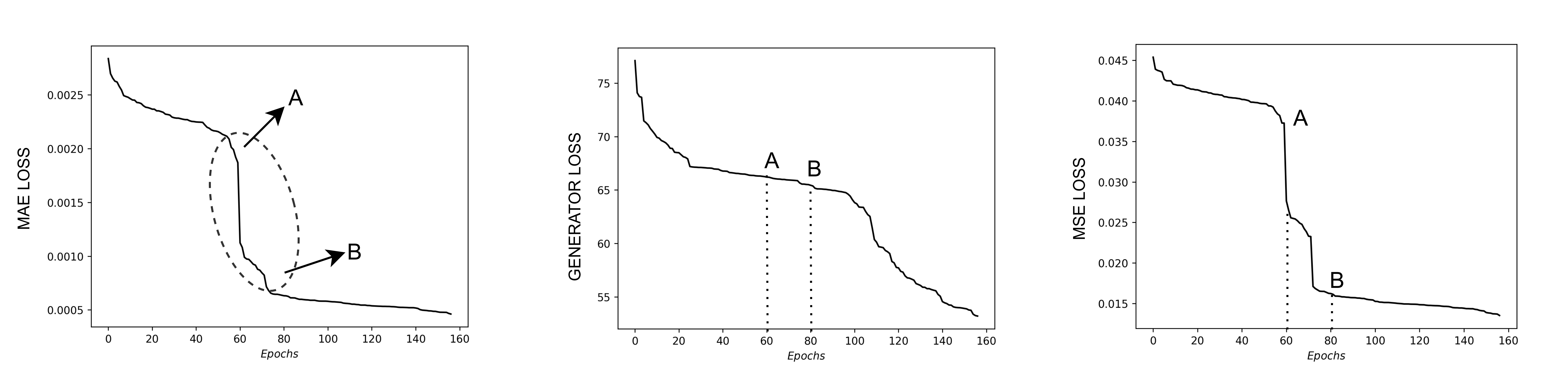
Training Loss Curve
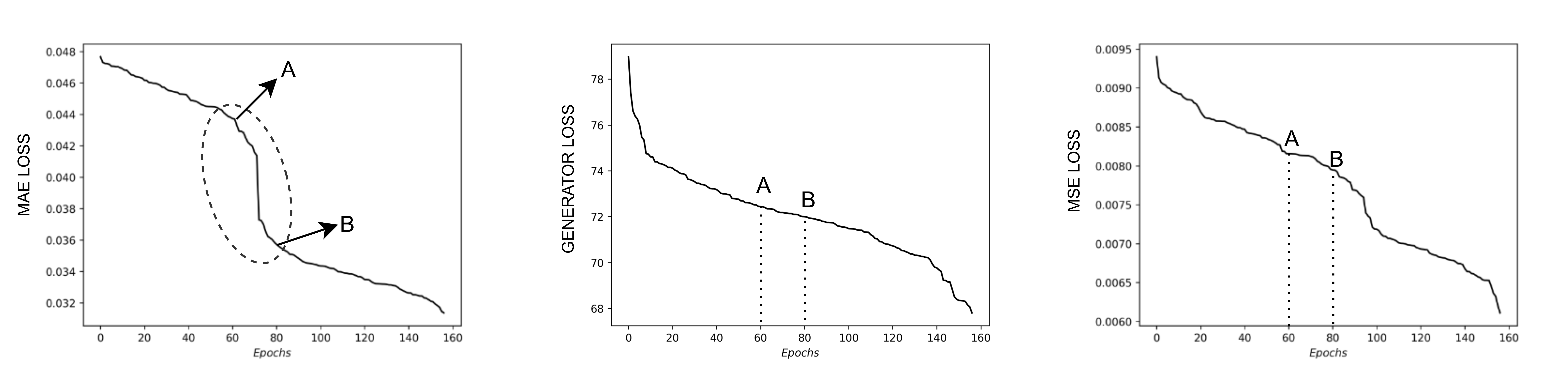
Validation Loss Curve