This Project was completed as part of my Research in the Kumar Robotics Lab at UPenn
This project is a Extension of Classical Frontier based Exploration strategies to Learning based Exploration
Using Learning based approaches allow for a continual improvement of the Exploration stack's behavior and a possible reduction in the Time of Exploration
Typically, we calculate the quality of Exploration using,
1. Total coverage.
2. Time to n% coverage.
The Total coverage is a measure of the total explored area divided by the total map area
Intuitively, the time to n% coverage calculates how fast a strategy explores a given unknown environment
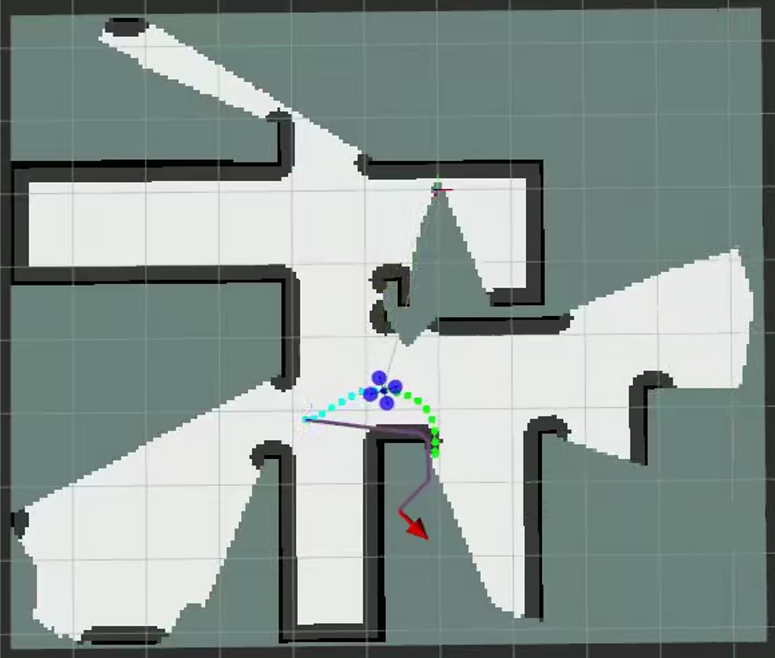
Coming to the Reinforcement Learning part, We define the action space to contain 8 different directions in which a Quadrotor can take a step.
For this approach, the State space is the 2D Occupancy grid representation of the Map. At every position, the agent must decide the most favourable direction to move in
We then use the PPO algorithm for training the Reinforcement Learning Agent.

We use the same setup as used in the Classical Frontier Based Exploration stack.
Sample Figures and a Video of the Exploration Process